On stochastic gradient descent
What happens if someone uses stochastic gradient descent with batch size one in a simple linear regression problem? Does the estimator converge to the OLS estimator which uses the full data?
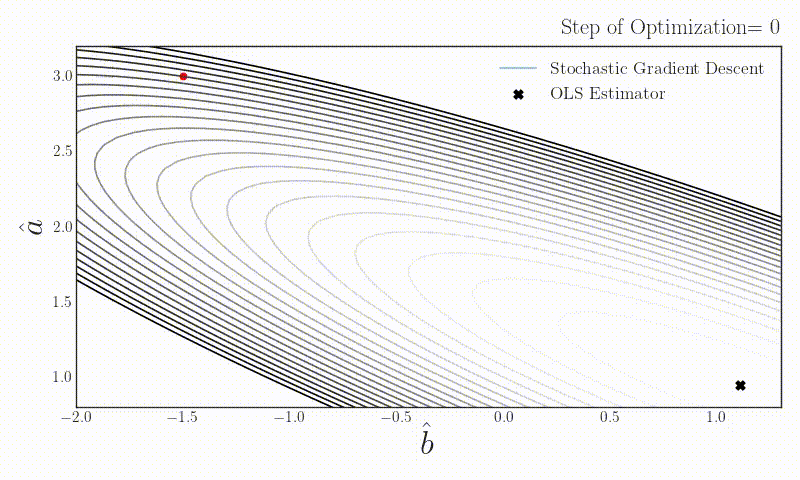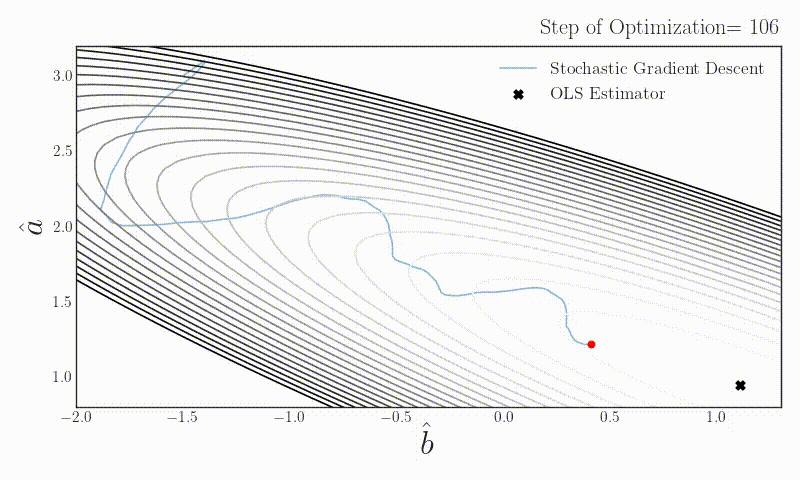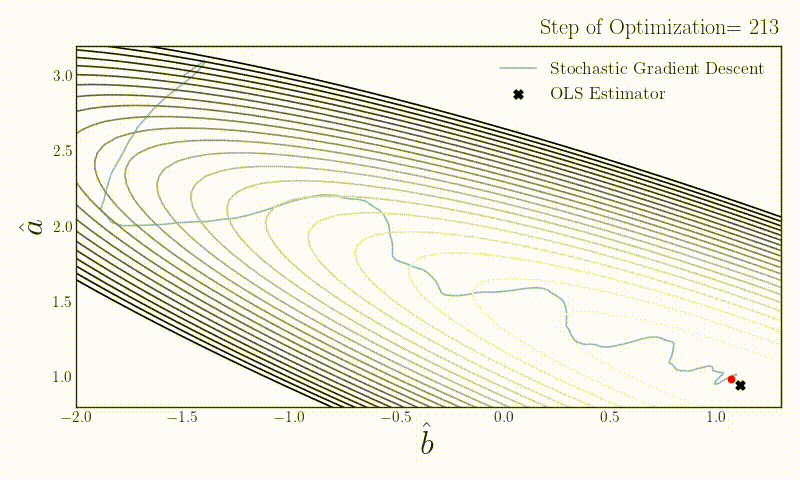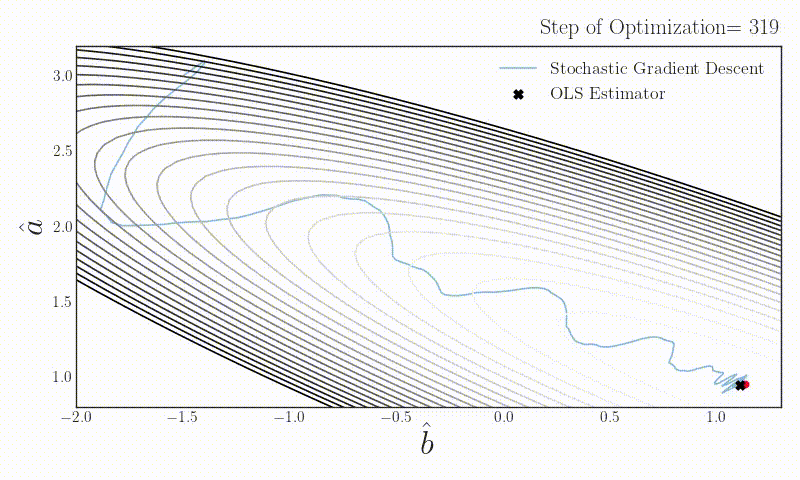
How does a deep neural network solve a recursive dynamic problem: A simple example
Using deep neural nets to solve an optimal control problem. Example from Recursive Macroeconomic Theory by Lars Ljungqvist and Tom Sargent, 3rd edition, Exercise 5.11
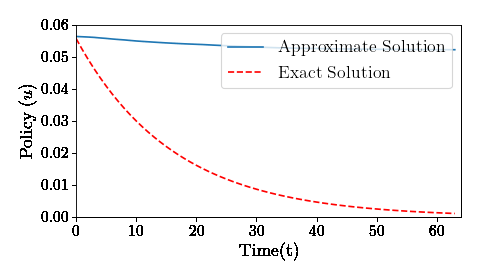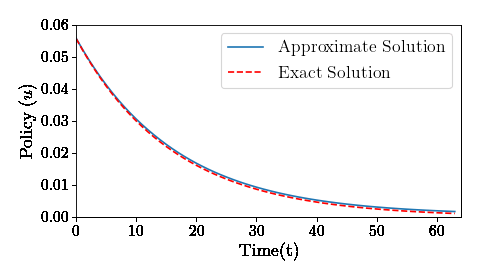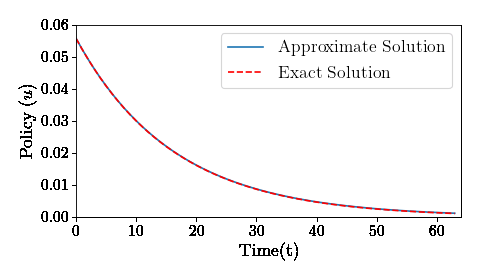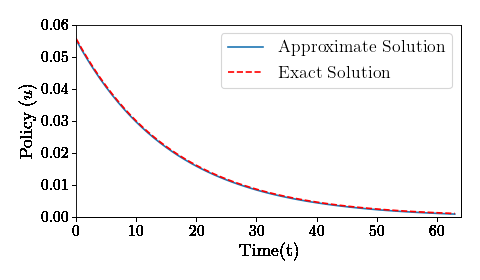
Having fun with the Law of Large Numbers
The code is written as a gift for a great teacher and mentor

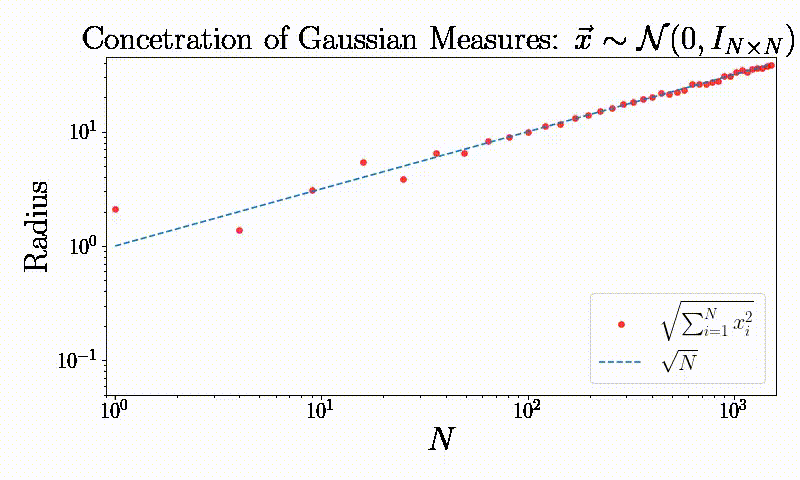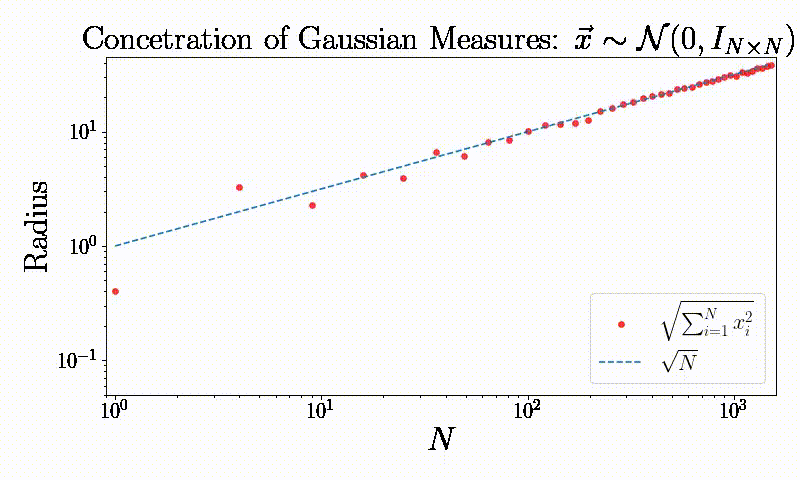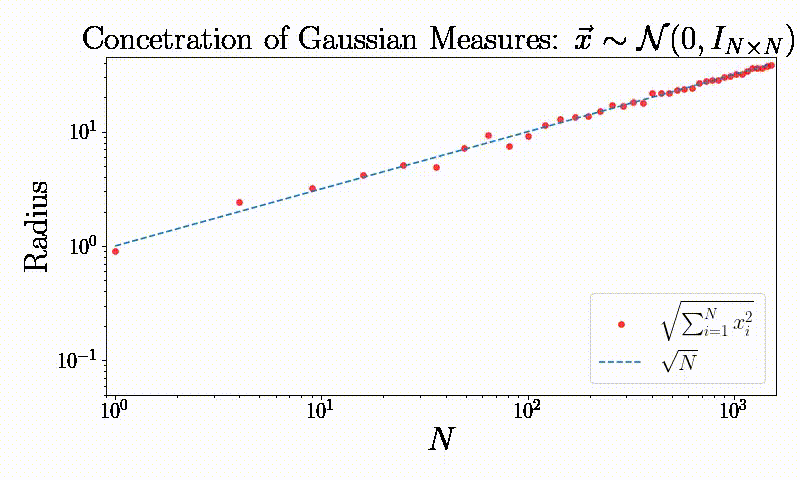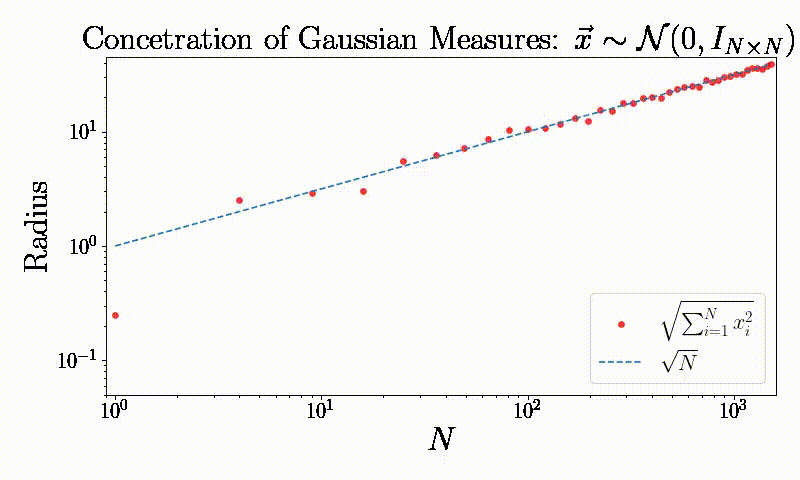
Concentration of measures: A simple observation
“It is of course impossible to even think the word Gaussian without immediately mentioning the most important property of Gaussian processes, that is concentration of measure.” M. Talagrand
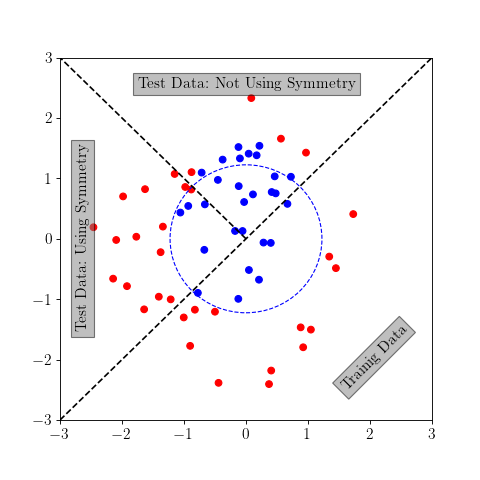
Symmetry: Dimensionality reduction and generalization (Working on it)
Symmetry as an a priori information can lead to extensive dimensionality reduction (alleviation of curse of dimensionality) and extreme generalization power. I provide two examples: rotation and permutation invariance